引言
在项目的开发中,代码分层经常简单划分为 Controller、Service、Mapper三层,但是并没有把职责边界划分清晰。经常会出现以下情况:
Controller层出现业务逻辑。Service层大而笨重,甚至有可能在Service层出现Mapper层应关心的Sql拼接等问题。
这样往往造成代码无法复用,并且各分层的职责边界不清晰,后续代码维护起来会非常麻烦。
在真正的团队开发中,每个人的习惯、代码风格都不同,写出来的代码必然带着自己的标签,后续其他人维护的时候,是按着自己的习惯修改还是遵循编码者的风格,又是个艰难的选择,如果都随心所欲,长久以此势必造成代码晦涩难懂,难以维护。
所以一个好的应用分层需要具备以下几点:
- 方便后续代码进行维护扩展;
- 分层的效果需要让整个团队都接受;
- 各个层职责边界清晰。
如何分层
从我们的业务开发中总结了一个较为理想的模型,如下图:
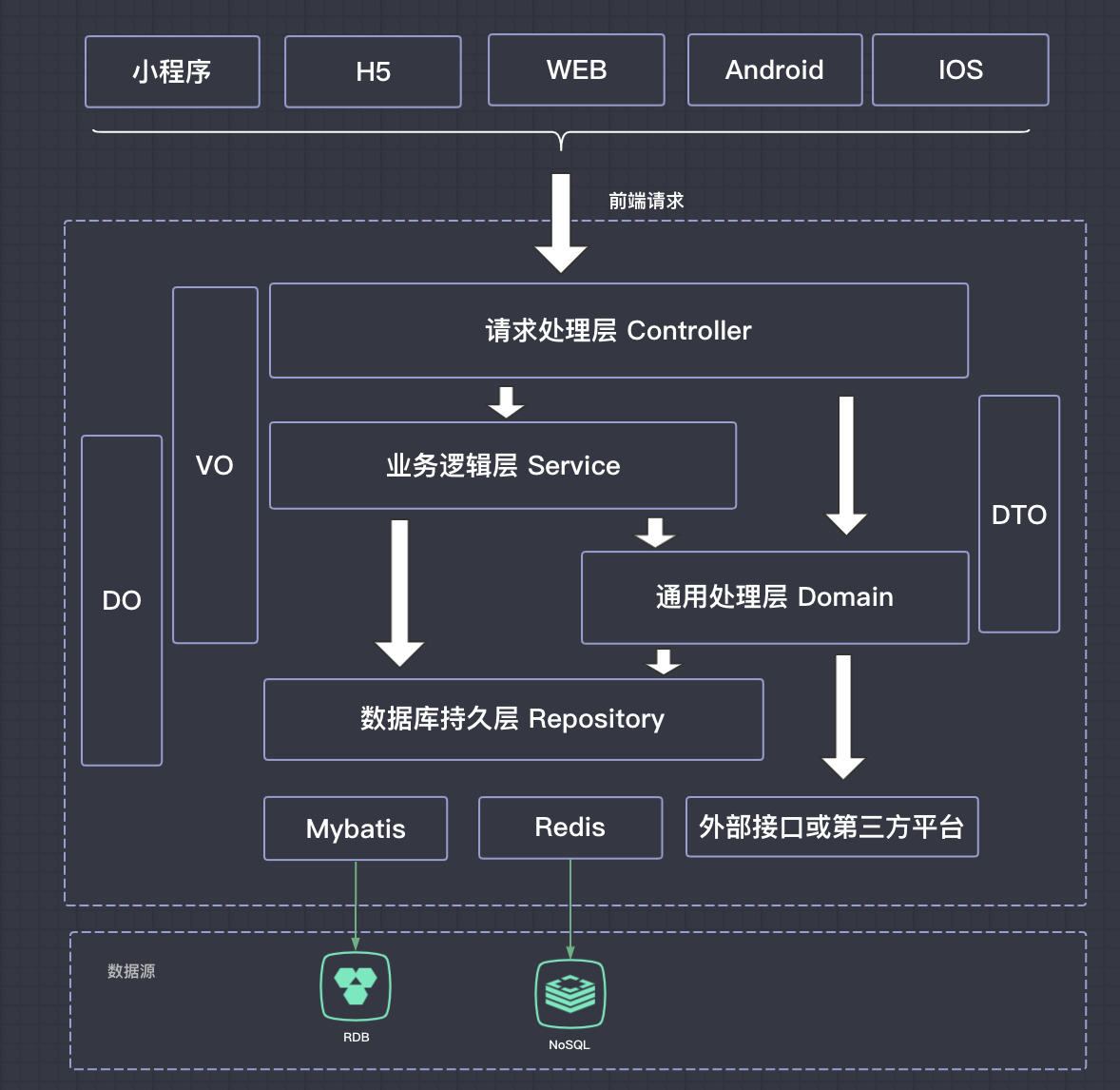
图中默认上层依赖于下层,箭头关系表示可直接依赖,如:Controller层可以依赖于 Service 层,也可以直接依赖于 Domain 层,依此类推。
Controller:最上层Controller是分层模型的第一层:轻业务逻辑,参数校验,异常兜底。Service:业务层,复用性较低,这里推荐每一个Controller方法都得对应一个Service,不要把业务逻辑放在Controller中去做。Domain:通用业务处理层(可复用逻辑层)。- 这里的
Domain可以是单个服务的,比如RedisDomain、字典DictDomain、短信发送SmsDomain;也可以是复合的,比如逻辑上的连表查询等。 - 它有如下特征:
- 1) 对第三方平台封装的层,预处理返回结果及转化异常信息;
- 2) 对
Service层通用能力的下沉,如缓存方案、中间件通用处理; - 3) 与
Repository层交互,对多个Repository的组合复用。
- 这里的
Repository:数据访问层,与底层数据源进行交互。- 外部接口或第三方平台:包括其它部门 RPC 开放接口,基础平台,其它公司的 HTTP 接口。
领域模型
- VO(View Object):显示层对象,通常是
Web向模板渲染引擎层传输的对象。 - DTO(Data Transfer Object):数据传输对象,
Service或Domain向外传输的对象。 - DO(Data Object):与数据库表结构一一对应,通过
Repository层向上传输数据源对象。
| 分层 | 领域模型 |
|---|---|
| Controller | VO |
| Service/Domain | VO/DTO/DO |
| Repository | DO |
各分层操作自己分层对应的领域模型,不允许该分层的领域模型出现在其他的分层中,不然就会使职责边界不清晰。
禁止使用 Map 来传输参数。
这里摘取他人的回答:
1、Map 参数数量大时不易维护。要通过识别字符串形式的 key,可能哪个字母没加程序就出错了。
2、Map 转成实体,耗费资源。或者不转实体,直接将 Map 传到 sql 层,但要判断空值(传没传这个参数?),参数数量一多要加一堆判断(sql 效率下降,也不易维护)
3、创建 Map 再 put 进参数值,比创建一个实体类的时间要长(Map 数量少时创建的时间差距很小,但是数量较大时差距会非常大)
4、参数类型的控制。sql 中不是字符串类型的参数还要转成数值。
5、不利于他人共同开发和后期维护。
6、Map.put(key,value) 乱传的问题不能在编译阶段发现,用 Javabean 可以精确定义参数类型和限制Map 的优点:
1、灵活性强于 Javabean,易扩展,耦合度低。
2、写起来简单,代码量少。
看一看 Javabean 的优点:
1、面向对象的良好诠释。
2、数据结构清晰,便于团队开发 & 后期维护。
3、代码足够健壮,可以排除掉编译期错误。
权衡利弊,如果团队开发还是 Javabean 比较好。
总结
一个好的分层会使代码的职责边界更加清晰,后续更容易扩展维护,以及更容易复用。
其实分层也需要根据不同的项目来具体分析,并没有一个标准的准则,一个好的分层只要能使代码职责清晰,便于扩展维护,就是一个好的分层。

